PAGERANKER
Web Graph Crawler and PageRank Authority Analyser
The Problem Statement
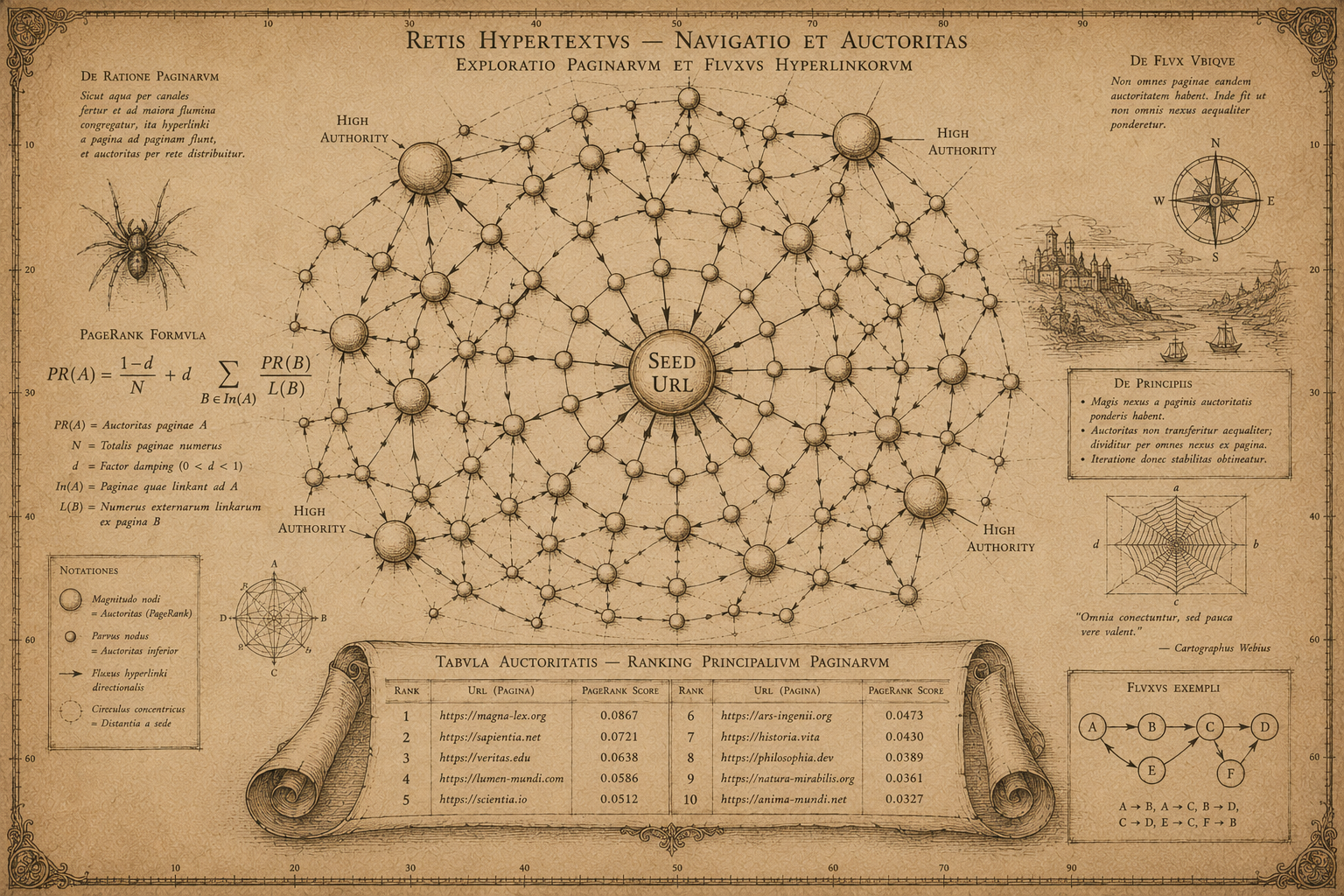
“Understanding web page authority requires both a crawler to discover the link graph and a ranking algorithm to compute relative importance — most academic PageRank implementations provide the algorithm without the crawler, or the crawler without ranking. PageRanker combines both into a single pipeline: it crawls a seed URL up to a configurable depth, builds the directed link graph, applies the iterative PageRank algorithm until convergence, and surfaces the top-authority pages. It operates as the analytical middle ground between a raw link extractor and a full search engine index, making link authority visible and explorable.”
The Architecture Layout
The crawler module uses Python requests with async queue management to fetch HTML pages concurrently, extracting all anchor href attributes and normalising relative URLs to absolute form. The graph builder constructs a directed adjacency list as pages are discovered, with nodes representing URLs and directed edges representing hyperlinks. Once crawling completes to the configured depth, the PageRank engine initialises each node with equal weight (1/N) and iterates the PageRank formula — distributing each page's score among its outbound links with a damping factor of 0.85 — until delta between iterations falls below convergence threshold. Results are sorted by final score and displayed as a ranked table with inbound link counts and domain statistics.
Architecture Design Diagram